R guide
A quick reference guide and sample code for statistical programming in R
Brendon Smith
br3ndonland
Source code on
GitHub

Intro
R is an interpreted computer language used primarily for statistical analysis.
From the R FAQ:
R is a system for statistical computation and graphics. It consists of a language plus a run-time environment with graphics, a debugger, access to certain system functions, and the ability to run programs stored in script files.
The design of R has been heavily influenced by two existing languages: Becker, Chambers & Wilks’ S (see What is S?) and Sussman’s Scheme. Whereas the resulting language is very similar in appearance to S, the underlying implementation and semantics are derived from Scheme. See What are the differences between R and S?, for further details.
The core of R is an interpreted computer language which allows branching and looping as well as modular programming using functions. Most of the user-visible functions in R are written in R. It is possible for the user to interface to procedures written in the C, C++, or FORTRAN languages for efficiency. The R distribution contains functionality for a large number of statistical procedures. Among these are: linear and generalized linear models, nonlinear regression models, time series analysis, classical parametric and nonparametric tests, clustering and smoothing. There is also a large set of functions which provide a flexible graphical environment for creating various kinds of data presentations. Additional modules (‘add-on packages’) are available for a variety of specific purposes (see R Add-On Packages).
The name is partly based on the (first) names of the first two R authors (Robert Gentleman and Ross Ihaka), and partly a play on the name of the Bell Labs language ‘S’, which stood for System.’
General R resources
- Read the R FAQ. GNU General Public License.
- R documentation provides a comprehensive listing of R packages that are available in CRAN, BioConductor and GitHub.
- R in Action by Robert Kabacoff is an excellent reference guide. If I had to recommend one single resource, I would direct you here. Second edition copyright 2015 by Manning Publications Co. All rights reserved.
- Quick-R by Robert Kabacoff. Great quick reference. Copyright Robert I. Kabacoff, PhD.
- Cookbook for R by Winston Chang. CC BY-SA 3.0 license (freely shared and adaptable)
- R Graphics Cookbook by Winston Chang (mostly for ggplot2). CC0 1.0 license (public domain dedication, no copyright).
- The R book by Crawley
- simpleR PDF by Verzani. Copyright John Verzani, 2001-2. All rights reserved. This book is frequently referenced, but outdated (‘Appendix: Teaching Tricks’ recommends distributing R code to students on ‘floppies.’)
- Linear models in R by Faraway. Copyright 2014 by Taylor & Francis Group, LLC.
Setup
Installation
I highly recommend using a package manager to install R and RStudio. Otherwise, R and RStudio must be downloaded and installed separately. R cannot be updated from within RStudio, and installing a new R version can require reinstallation of packages. It’s difficult to manage.
Install Homebrew. Homebrew includes Homebrew-Cask to manage other macOS applications.
- I previously used Anaconda to manage my Python and R distributions, and now use Homebrew. I switched because Anaconda is a very large installation, and not as flexible or general as Homebrew. Conda and brew are sort of like competing package managers.
Click here for Anaconda info
Anaconda
- I install Anaconda by direct download. I have also tried installing via Homebrew Cask, but didn’t get the correct command prompt or path.
- Anaconda contains the Conda and
PyPI (pip) package managers.
Packages can be installed from
pip, and will integrate into the Anaconda environment. - Conda commands:
- Check installed packages with
$ conda listand$ pip list. - Find packages with
$ conda search. - Update conda with
$ conda update --prefix <PATH> anaconda - Update packages with
$ conda update --all
- Check installed packages with
Additions to the standard Anaconda install
- R and RStudio
When I was working with R, I preferred to install R and RStudio via Anaconda for easier version and package management. Otherwise, R and RStudio must be downloaded and installed separately. R cannot be updated from within RStudio, and installing a new R version can require reinstallation of packages. It’s just too difficult to manage.
Install R and RStudio via Homebrew
Update Homebrew regularly with
brew updateandbrew upgradeCheck health of installation with
brew doctorSee docs for further info.
My RStudio setup
- Preferences
- Appearance
- Modern RStudio theme
- Material editor theme
- Dank Mono font
- Code
- Editing
- Insert spaces for tab
- Tab width: 2
- Saving
- Strip trailing horizontal whitespace when saving
- Editing
- R Markdown
- Show document outline by default
- Appearance
- Information on other RStudio options can be found in the RStudio documentation.
Working with R files
I highly recommend working with a notebook file format. Jupyter Notebook and R Markdown are the most popular formats.
Jupyter Notebook
- Jupyter Notebook is a file format most widely used for scientific computing. It supports many programming languages, including Python and R. Jupyter Notebook files enable creation of reproducible computational narratives containing Markdown text interspersed with functional code chunks.
- Jupyter Notebook files can be run with JupyterLab.
- JupyterLab is a development environment produced by Project Jupyter.
- JupyterLab can run Jupyter Notebooks, R Markdown, Markdown, and many other file formats.
- Install Jupyter with Homebrew or the Python
pipmodule manager. I previously used Anaconda to manage my Python and R distributions, and now use Homebrew. I switched because Anaconda is a very large installation, and not as flexible or general as Homebrew. - Launch from the command line with
jupyter notebookor
- Google provides a cloud-based Jupyter Notebook environment called Colaboratory.
- See my R-proteomics-Nrf1 repo for an example of notebook formats.
R Markdown
- R Markdown is a document creation package based on Markdown, a syntax for easy generation of HTML files, and Pandoc, a document output and conversion system.
- Markdown resources
- I have provided a guide to Markdown syntax on GitHub.
- MarkdownGuide
- GitHub-Flavored Markdown
- R Markdown resources
- Pandoc resources
- To create an R Markdown document in RStudio, File -> New File -> R Markdown.
- An RMarkdown file contains three types of data:
- YAML front matter header at the top of the file to specify output methods
- Markdown-formatted text
- Functional code chunks.
- When you click the Knit button the code will run and the output will be created.
- R Markdown has started offering a Notebook output format that is similar to the Jupyter Notebook. See the output formats section.
YAML front matter header
- The header specifies a document title and subtitle, table of contents, and output options.
Functional code chunks
- In addition to the standard Markdown inline code chunks and Markdown fenced code chunks, RMarkdown includes functional language-specific code chunks that allow code to be run from within the Markdown document.
- RMarkdown code chunks are inserted with a modified Markdown code
fence format:
- Normal Markdown code chunks are enclosed within triple backticks, with the language name after the first set of backticks.
- Functional R code is specified with
{r}after the first set of backticks. R will run this code when knitting the RMarkdown document. If you want to include a standard Markdown code chunk without running the code in R, leave out the curly braces. - Conclude the code chunk with another set of triple backticks.
- See the R Markdown code chunks page for more info.
Example:
## speed dist
## Min. : 4.0 Min. : 2.00
## 1st Qu.:12.0 1st Qu.: 26.00
## Median :15.0 Median : 36.00
## Mean :15.4 Mean : 42.98
## 3rd Qu.:19.0 3rd Qu.: 56.00
## Max. :25.0 Max. :120.00Change size of figures (at beginning of r code chunk in brackets):
{r, out.width = '1000px', out.height = '2000px'}Prevent printing of code in HTML output:
echo=FALSE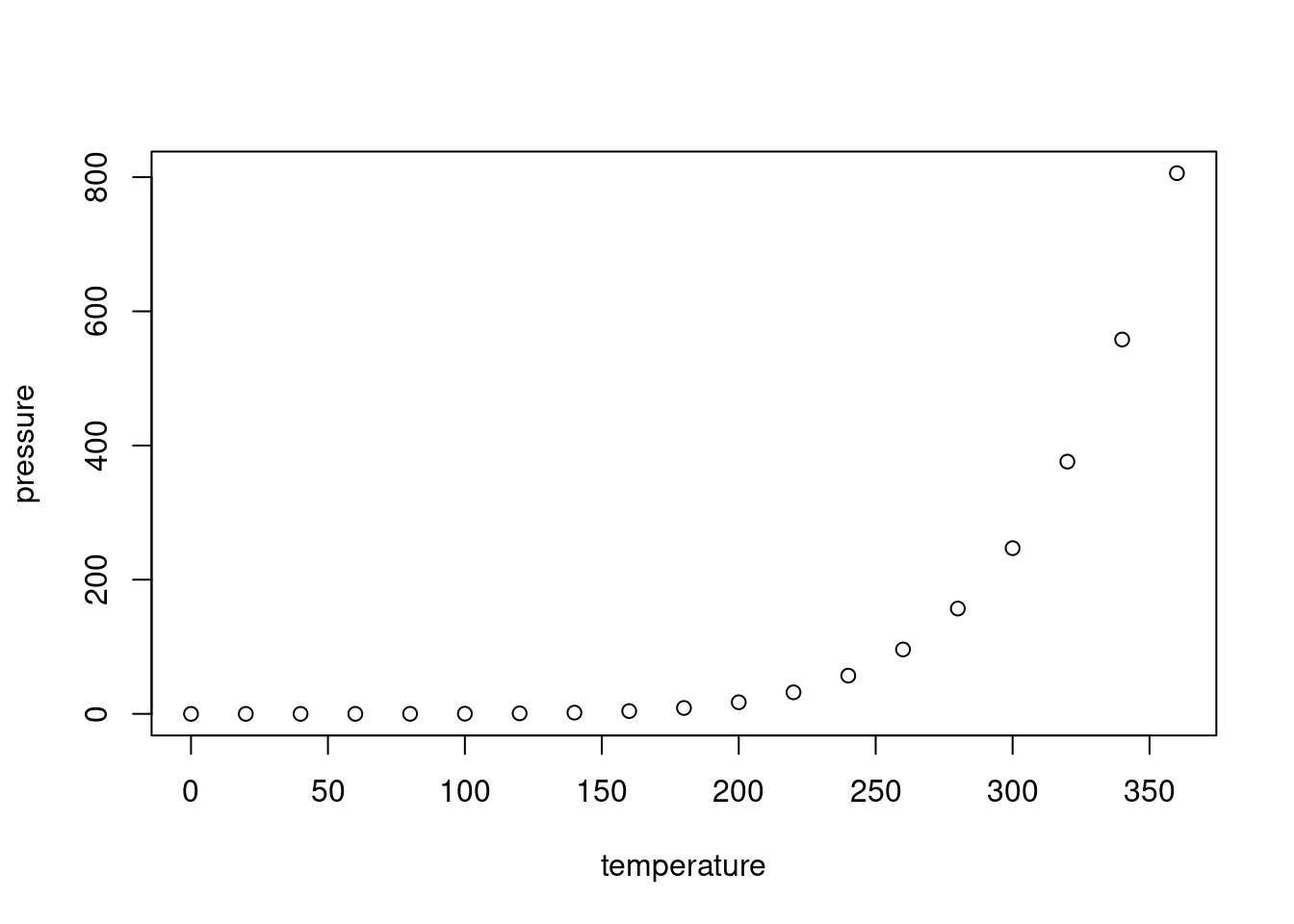
Output formats
- There are many formats available. RMarkdown documents can easily be interconverted among the formats.
- Only one output format can be specified at a time.
- When a report is knit, it will appear in the RStudio viewer, and will automatically be saved to the same directory as the .rmd file.
- The
github_documentoutput format outputs a GitHub-friendly Markdown file. It is RStudio-specific, not a Pandoc standard, and provides some RStudio-specific benefits like local HTML preview.At the time of this writing, the markdown output formats (either
github_documentormd_document: variant: gfm) don’t seem to be outputting a table of contents, even whentoc: trueis included. The solution is to include a separate header file containing the header and TOC.
- The R Notebook format is similar to a Jupyter Notebook. Code chunks can be executed independently and interactively, rather than having to knit the entire workbook. I haven’t found it to be useful, and would prefer to use a Jupyter Notebook.
- R Markdown can build websites.
- This website was generated with the simple R Markdown static site builder.
- The
blogdownpackage is used to build the site within RStudio. - The _site.yml file specifies the website build parameters. The website builds into the docs directory for compatibility with GitHub Pages.
- The static site builder uses Bootstrap, and themes come from Bootswatch. For more info on themes
and options, see the R
Markdown HTML document docs or run
?rmarkdown::html_document.
RStudio Projects
RStudio
Projects are the best way to manage code in RStudio. RStudio
projects make it straightforward to divide your work into multiple
contexts, each with their own working directory, workspace, history, and
source documents. Projects allow use of version control with Git.
Installing packages into the project locally with renv is
very helpful.
R packages
- Packages are programs written for R that provide additional functionality. R is dependent on large numbers of packages.
renvis a package dependency management system for R projects. It helps avoid problems caused by different package versions and installations by giving each project its own isolated package library.renvis separate from general package managers like Homebrew used to install R and RStudio.- This project previously used Packrat, a predecessor to
renvthat is now “soft-deprecated.”- Migration from Packrat to
renvis simple. Run the following command in the console:renv::migrate("~/path/to/repo"). - Then if packages aren’t already installed, run
renv::restore(), or in the Packages pane, navigate torenv-> Restore Library.
- Migration from Packrat to
Git and GitHub
- Version control is highly recommended for code of all kinds. Git is a free and widely used version control system.
- RStudio provides a version control guide for linking with Git.
- Git has a substantial learning curve. RStudio and GitHub have helpful documentation for getting started.
- The directory where the files are located must be formatted as an R Project.
Coding practice
Hands-on coding practice is essential.
- Read An Introduction to R and complete the sample session in Appendix A.
- DataCamp is extremely helpful. I took the ‘Introduction to R,’ ‘Data Analysis and Statistical Inference,’ and ‘A hands-on introduction to statistics with R track-introductory’ courses.
Running code
- See the RStudio documentation on editing and executing code
- The basic code entry window is called the console. It is oriented towards entering and running code one line at a time, and does not allow you to save the code.
- In the RStudio source editor, to execute a single line of source
code where the cursor currently resides use
Cmd+Enter(or use the Run toolbar button). - There are three ways to execute multiple lines from within the
editor:
- Select the lines and press
Cmd+Enter(or use the Run toolbar button) - After executing a selection of code, use the Re-Run Previous Region command (or its associated toolbar button) to run the same selection again. Note that changes to the selection including additional, removal, and modification of lines will be reflected in this subsequent run of the selection.
- To run the entire document press
Cmd+option+R(or use the Source toolbar button). Using the Knit command in R Markdown documents will run the entire document.
- Select the lines and press
- The difference between running lines from a selection and invoking Source is that when running a selection all lines are inserted directly into the console whereas for Source the file is saved to a temporary location and then sourced into the console from there (thereby creating less clutter in the console).
- Source on save: Enabling source on save runs the code every time you save. When editing re-usable functions (as opposed to freestanding lines of R) you may wish to set the Source on Save option for the document (available on the toolbar next to the Save icon). Enabling this option will cause the file to automatically be sourced into the global environment every time it is saved. Setting Source on Save ensures that the copy of a function within the global environment is always in sync with its source, and also provides a good way to arrange for frequent syntax checking as you develop a function.
- The workspace is your current R working environment and includes imported datasets, vectors, data frames, and other objects.
- Workspace info persists after restarting R. To clear: In RStudio, Session -> Clear Workspace will reset the workspace (shown in the environment tab in RStudio). Click the broom icon in the environment, history and plots tabs to clear individually.
Basic syntax
- R can be used as a calculator if needed:
5+5,5-5,(5+5)/2, etc) - Use
<-or=to define a variable (also called an object in other languages like Python). For example,x <- 42orx = 42set x equal to 42. ~is similar to=in Python or SAS or a normal written equation. It means ‘versus’ or ‘as a function of.’- Use quotation marks to enter non-numeric values, called
‘strings.’ Entering
'forty-two'will treat forty-two as a word. Both single and double quotes can be used, but double quotes are preferred. - Logical Boolean values are entered with
TRUEorT, andFALSEorF. - You can check the data type of a variable by entering
class(var_name). - You can perform mathematical operations on variables, but only if they have a numerical value assigned.
- Print (view data) in R by simply typing the variable name. There is
no need to type
print(variable)like Python or PROC PRINT like in SAS. - Hit tab when typing a function to call up a list of suggestions with explanations.
- Use
apropos()to help identify the proper function to use. - The help function can be called up by typing
?followed by the command of interest - The arrow keys can be used to scroll through previous commands (see p.2 of Verzani simpleR PDF)
- R is case-sensitive, so true and TRUE are treated differently.
- Adding comments or notes to your code:
- In RStudio, you can comment and uncomment code using the Edit -> Comment/Uncomment Lines menu item (or Cmd+Shift+C).
- Begin comments with
#, similar to how you would use a star to begin a note and a semicolon to conclude it in SAS. A note in R will begin after#and continue until the end of the line (until you insert a line break with enter). - You can also use a semicolon instead of a line break to indicate the end of a command.
Data structures
R vs. SAS from Quick-R:
Unlike SAS, which has DATA and PROC steps, R has data structures (vectors, matrices, arrays, data frames) that you can operate on through functions that perform statistical analyses and create graphs. In this way, R is similar to PROC IML.
See R in Action 2.2 for further info.
Vector
The vector is a way to store data in R. Vectors are created with the combine function
c(). Enter values or variable names separated by commas:You can also name the elements of a vector, and create a variable with the vector names for ease of use.
Select parts of a vector with brackets. For example, to create a new vector with a specific portion of another vector, type
R stores vectors as strings of data. To put the data in table format, use a data frame (see below).
Matrix
From DataCamp introduction to R course:
In R, a matrix is a collection of elements of the same data type (numeric, character, or logical) arranged into a fixed number of rows and columns. Since you are only working with rows and columns, a matrix is called two-dimensional. You can construct a matrix in R with the matrix function, for example:
The first argument is the collection of elements that R will arrange into the rows and columns of the matrix. Here, we use
1:9which constructs the vectorc(1,2,3,4,5,6,7,8,9). The argumentbyrowindicates that the matrix is filled by the rows. If we want the vector to be filled by the columns, we just placebycol=TRUEorbyrow=FALSE. The third argumentnrowindicates that the matrix should have three rows.
You can use vectors to name rows and columns of a matrix, for example:
The
rowSums(matrix_name)andcolSums(matrix_name)functions will sum the matrix (the first S is capital).Use the
cbind()function to merge vectors and matrices.Similar to vectors, use square brackets
[ ]to select elements from a matrix. Whereas vectors have one dimension, matrices have two dimensions. You should therefore use a comma to separate that which you want to select from the rows from that which you want to select from the columns. For example:my_matrix[1,2]first row, second element.my_matrix[1:3,2:4]rows 1,2,3 and columns 2,3,4.- If you want to select all elements of a row or a column, no number
is needed before or after the comma:
my_matrix[,1]all elements of the first column.my_matrix[1,]all elements of the first row.
- Just like
2*my_matrixmultiplied every element of my_matrix by two,my_matrix1 - my_matrix2creates a matrix where each element is the product of the corresponding elements inmy_matrix1andmy_matrix2.
Similar to vectors, the standard operators like
+ - / *etc. work in an element-wise way on matrices in R. For example:2*my_matrixmultiplies each element ofmy_matrixby two.
Factor
The factor is an R function used to store categorical variables.
To create factors in R, use the function
factor(). First, create a vector that contains the observations to be converted to a factor. For example,gender_vectorcontains the sex of 5 different individuals andparticipants_1contains discrete numbers representing deidentified study participants:When you first get a data set, you will often notice that it contains factors with specific factor levels. However, sometimes you will want to change the names of these levels for clarity or other reasons. R allows you to do this with the function
levels():To create an ordered factor, you have to add two additional arguments:
By setting the argument
ordered=TRUEin the functionfactor(), you indicate that the factor is ordered. With the argumentlevelsyou give the values of the factor in the correct order:
Here’s an example within a functional R Markdown code block:
# Create a vector of temperature observations
temperature_vector <- c('High', 'Low', 'High', 'Low', 'Medium')
# Specify ordinal variables with given levels
factor_temperature_vector <- factor(temperature_vector,
order = TRUE,
levels = c('Low', 'Medium', 'High'))
# Display the vector
factor_temperature_vector## [1] High Low High Low Medium
## Levels: Low < Medium < HighData frame
A data frame is a combination of vectors that functions like a spreadsheet within R.
Variables are columns, observations are rows.
Different types of vectors can be combined into a data frame, as long as the vectors have the same length.
This is also how datasets are organized in SAS.
Example data frame mtcars:
## [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"
## [11] "carb"## mpg cyl disp hp drat wt qsec vs am gear carb
## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1## mpg cyl disp hp drat wt qsec vs am gear carb
## Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.7 0 1 5 2
## Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.9 1 1 5 2
## Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.5 0 1 5 4
## Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.5 0 1 5 6
## Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.6 0 1 5 8
## Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.6 1 1 4 2## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...## [1] 32 11- The function
str()shows you the structure of your dataset. For a data frame it provides:- The total number of observations (e.g. 32 car types)
- The total number of variables (e.g. 11 car features)
- A full list of variable names (e.g. mpg, cyl … )
- The data type of each variable (e.g. num for car features)
- The first observations.
- Also see Verzani simpleR Appendix: A sample R session for more with the built-in mtcars dataset.
Example from DataCamp Introduction to R course:

Remember that a data frame is essentially a combination of vectors. The DataCamp example above created the data frame in two steps for instructional purposes, but you can usually build this in to the
data.framecommand.To create a data frame on planets sorted by decreasing diameter (example from DataCamp):
Selecting parts of data frames
- Similar to vectors and matrices, select parts of a data frame with
square brackets
[ ]in the formmy_data_frame[rows,columns].my_data_frame[1,2]selects the second element from the first row inmy_data_frame.my_data_frame[1:3,2:4]selects rows 1,2,3 and columns 2,3,4 inmy_data_frame.my_data_frame[1,]selects all elements of the first row.
- Selecting part of a data frame column:
- Maybe you want to select only the first 3 elements of the variable
typefrom theplanetsdata frame. - One way to do this is:
planets_df[1:3,1]. You have to know (or look up) the position of the variabletype, which gets hard if you have a lot of variables. - It is often easier to just make use of the variable name,
e.g.
planets_df[1:3,'type'].
- Maybe you want to select only the first 3 elements of the variable
- Selecting an entire data frame column:
- If you want to select all elements of the variable
rings, bothplanets_df[,5]andplanets_df[,'rings']work. - Use the
$sign to tell R that it only has to look up all the elements of the variable behind the sign:df_name$var_name. You can combine this with the element section above:df_name$var_name[rows]. Note that you do not need to specify a column because it is already specified by the variable name.
- If you want to select all elements of the variable
- Selecting parts of a data frame conditionally:
The
subset()function selects a subset of a data frame according to conditions you specify.subset(df_name, some.condition== 'condition'). The first argument ofsubset()specifies the dataset for which you want a subset. By adding the second argument, you give R the necessary information and conditions to select the correct subset. Examples:subset(planets_df, subset=(planets_df$rings == TRUE)) subset(planets_df, subset=(planets_df$diameter<1)) very_good = subset(cdc,cdc$genhlth=='very good') age_gt50 = subset(cdc,cdc$age>50) red_wine <- subset(wine_data, wine_data[, 1]=='Red') red_usa <- subset(red_wine_data, red_wine_data$condition == 'USA')The second
subset=inside the parentheses may not be necessary.Conditions can be used with logical operators
&and|.- The
&is read ‘and’ so thatsubset(cdc, cdc$gender == 'f' & cdc$age > 30)will give you the data for women over the age of 30.under23_and_smoke = subset(cdc,cdc$age<23 & cdc$smoke100==T)will select respondents who are under the age of 23 and have smoked >100 cigarettes. - The
|character is read ‘or’ so thatsubset(cdc, cdc$gender == 'f' | cdc$age > 30)will select people who are women or over the age of 30. - In principle, you may use as many ‘and’ and ‘or’ clauses as you like in a subset.
- The
Sorting data frames
Sort data frames with
order().order()is a function that gives you the position of each element when it is applied on a variable. Let us look at the vector a:a <- c(100,9,101). Noworder(a)returns 2,1,3. Since 100 is the second largest element of the vector, 9 is the smallest element and 101 is the largest element.- Subsequently,
a[order(a)]will give you the ordered vector 9,100,101, since it first picks the second element of a, then the first and then the last.
Example from my postdoc Nrf1 proteomics experiments:
# Groups in alphabetical order groups <- c('lacZ', 'Nrf1-HA bort', 'Nrf1-HA chol', 'Nrf1-HA chow') groups[order(groups)]## [1] "lacZ" "Nrf1-HA bort" "Nrf1-HA chol" "Nrf1-HA chow"# Put groups in my preferred order ordered = factor(groups, levels = c('lacZ', 'Nrf1-HA chow', 'Nrf1-HA chol', 'Nrf1-HA bort')) # Verify desired order of groups groups[order(ordered)]## [1] "lacZ" "Nrf1-HA chow" "Nrf1-HA chol" "Nrf1-HA bort"- Make sure you refer to the new sorted variable
(
Orderedgroupsin this case) in subsequent code.
- Make sure you refer to the new sorted variable
(
Example: Reordering columns in a data frame from Cookbook for R:
# A sample data frame data <- read.table(header = TRUE, text = ' id weight size 1 20 small 2 27 large 3 24 medium ') # Reorder by column number data[c(1, 3, 2)]## id size weight ## 1 1 small 20 ## 2 2 large 27 ## 3 3 medium 24## size id weight ## 1 small 1 20 ## 2 large 2 27 ## 3 medium 3 24The above examples index into the data frame by treating it as a list (a data frame is essentially a list of vectors). You can also use matrix-style indexing, as in data[row, col], where row is left blank.
## id size weight ## 1 1 small 20 ## 2 2 large 27 ## 3 3 medium 24The drawback to matrix indexing is that it gives different results when you specify just one column. In these cases, the returned object is a vector, not a data frame. Because the returned data type isn’t always consistent with matrix indexing, it’s generally safer to use list-style indexing, or the drop=FALSE option:
## weight ## 1 20 ## 2 27 ## 3 24## [1] 20 27 24# Matrix-style indexing with drop=FALSE # preserves dimension to remain data frame data[, 2, drop = FALSE]## weight ## 1 20 ## 2 27 ## 3 24Another example from Stack Overflow
Create the data frame
dd <- data.frame( b = factor( c('Hi', 'Med', 'Hi', 'Low'), levels = c('Low', 'Med', 'Hi'), ordered = TRUE ), x = c('A', 'D', 'A', 'C'), y = c(8, 3, 9, 9), z = c(1, 1, 1, 2) ) dd## b x y z ## 1 Hi A 8 1 ## 2 Med D 3 1 ## 3 Hi A 9 1 ## 4 Low C 9 2Sort the frame by column z (descending) then by column b (ascending).
- You don’t have to put
decreasing=TRUElike the DataCamp examples, you can just put a negative sign before the column name (-z). You can use the
order()function directly without resorting to add-on tools – see this simpler answer which uses a trick right from the top of the example(order) code:Edit some 2+ years later: It was just asked how to do this by column index. The answer is to simply pass the desired sorting column(s) to the order() function, rather than using the name of the column (and
with()for easier/more direct access).
- You don’t have to put
Merging data frames
- Adding columns
To merge two data frames (datasets) horizontally, use the
mergefunction. In most cases, you join two data frames by one or more common key variables (i.e., an inner join).
- Adding rows
To join two data frames (datasets) vertically, use the
rbindfunction. The two data frames must have the same variables, but they do not have to be in the same order.If
data_frame_Ahas variables thatdata_frame_Bdoes not, then either:- Delete the extra variables in data frameA or
- Create the additional variables in data frameB and set them to NA
(missing) before joining them with
rbind( ).
Manipulating data frames
Stack and unstack using the PlantGrowth dataset included with R:
Unstackseparates out the groups into a data frame.
To create a boxplot of the three groups:
- General boxplots are made with
boxplot(independent_var~dependent_var). See the Plots section.
- General boxplots are made with
List
A list in R gathers a variety of objects under one name (that is, the name of the list) in an ordered way. These objects can be matrices, vectors, data frames, other lists, etc. The objects do not need to be related to each other.
To construct a list you use the function
list():The arguments to the list function are the list components. To name items in the list:
list(name1=your.component1, name2=component2,…)
Selecting elements from a list
Lists will often be built out of numerous elements and components. Getting a single element, multiple elements, or a component out of the list is not always straightforward.
List components can be selected with square brackets as usual, like
list[1].length()returns the total number of components in the list. For example, to identify the last actor in a list of actors in the movie The Shining:As with data frames, components can be referenced by name:
Adding elements to a list
- The concatenate function
c()is used to add elements to a list:c(list1,some.object) - If you want to give the new list item a name, you just add this to
the function:
c(list1,new.item.name=some.object)
Importing data into R
In RStudio, datasets can be loaded from CSV, from web using Tools -> Import dataset or by clicking Import dataset in the environment pane.
CSV file
This is one of the best ways to read in a dataset. Note that the file path should be in UNIX format. UNIX file paths have forward slashes, Windows file paths have backslashes (‘whacks’).
- First row contains variable names, comma is separator
- Note the / instead of on mswindows systems
There are many other parameters that can be specified when reading in a dataset. See R help.
Excel file
Export the excel file to a CSV and follow instructions above, or use the xlsx package:
Website
URL must be enclosed in quotes to make it a string.
APIs
- R is less flexible than Python. Accessing Application Programming Interfaces (APIs) is one example of this.
- ProgrammableWeb shared a helpful guide to accessing APIs with R.
Manually
- Create vectors with the dataset numbers and then create a data frame with those vectors (see above).
- the
scan()function can be used to import a vector or list. - See R-data CRAN document, and Verzani simpleR Appendix: Entering Data into R for more info.
Working with data
Cleaning data
- The
dplyrpackage is one of the most popular for working with data in R. It is similar to Python Pandas. See Tom Augspurger’s Gist on dplyr and Pandas. na.omit(dataset_name$optional_var_name)will omit any missing values (usually labeled ‘NA’)
Attaching data
- Datasets are usually attached so that variables can be named without reference to the original dataset.
- Note that if the code is run repeatedly without detaching the dataset each time, a message in the console will explain that the variables are masked by the previously input variables of the same name.
- You can also detach() the dataset when you are done. Empty parentheses detach all variables in the workspace.
- From R help (article: ‘Attach Set of R Objects to Search Path’): ‘By attaching a data frame (or list) to the search path it is possible to refer to the variables in the data frame by their names alone, rather than as components of the data frame (e.g., in the example below, height rather than women$height).’
Exporting data frames
Exporting to a delimited text file:
- Where
xis the object andoutfileis the target file. For example, the statementwrite.table(mydata, 'mydata.txt', sep=',')would save the datasetmydatato a comma-delimited file named mydata.txt in the current working directory. Include a path (for example,'c:/myprojects/mydata. txt') to save the output file elsewhere. Replacingsep=','withsep='\t'would save the data in a tab-delimited file. By default, strings are enclosed in quotes (’’) and missing values are written asNA.
- Where
Exporting to an Excel workbook using the xlsx package:
Statistical models
Helpful resources for statistical modeling
- The R sample code page.
- R in Action
- R Graphics Cookbook by Winston Chang (from Cookbook for R creator)
- R-bloggers R tutorial series
- R documentation and Quick-R for reference
- UCLA IDRE website
- Chapter 11: Statistical Models in R from An Introduction to R
- Linear models in R by Faraway
- The R book by Crawley
- Guidelines for selection of statistical tests from UCLA and University of Alabama
Types of variables
- Quantitative
- Interval/continuous: A measured value where the distance between each value is the same (length, width, weight, blood cholesterol level). A subtype of continuous variable that has a true zero value (age, time, temperature in degrees K) is sometimes called a ratio variable.
- Discrete: having only counted integer values (# cells, # people)
- Qualitative
- Nominal: also called categorical. Variable with discrete names for levels (color, diet group)
- Ordinal: variable with names ranked and organized into levels (low/medium/high)
- Also see
- Stevens SS Science 1946, DOI: 10.1126/science.103.2684.677
- DataCamp introduction to statistics course lesson 1 video
- My course notes
- CPSC 440 Lecture Notes Chapter 01-03 slide 5
- CPSC 440 lab 1 slide 9
- PATH 591 Lecture 05 A
Basic statistics
Mean:
mean()Groups of means can be compared with the
by()function:
Median:
median()Variance:
variance()Absolute value:
abs(x)Square root:
sqrt(x)Log:
log(x)Computing summary statistics of data subsets:
aggregate(model_formula, df_name, mean). This function is useful if you want to calculate means of each group in a dataset.Frequency table (to count the number of times each category occurs in a data frame):
table(df_name)For a specific variable:
table(df_name$var_name)The
tablecommand can also be used to combine multiple vectors of different types into a table:
Relative frequency table:
The
summary()function gives you an overview description of a variable (minimum, first quartile, median, mean, third quartile, and maximum). Thedescribe()function is similar, but includes more information on the distribution (sd, range, skew, kurtosis). Remember that skew is classified by the direction of the data tail.Using comparisons is a good way to facilitate data analysis.
To select all elements of a vector that are greater than zero, type
new_vector_name <- vector_name >0To compare vectors/variables (can also use
<or==):To compare multiple elements of a vector:
To create a ratio:
Proportion:
You can calculate a proportion based on a subset of the data. Example:
Sum vectors with the
sum()function, and compare sums withvar_name>other_var_name.The
scale()function converts values to z scores.
Confidence intervals
95% confidence for a sample size n means that 95% of random samples of size n will yield confidence intervals that contain the true average value.
The margin or error is equal to the radius (or half the width) of the confidence interval.
Sample code:
Calculating the critical value for a confidence interval:
qnorm(0.95)Margin of error:
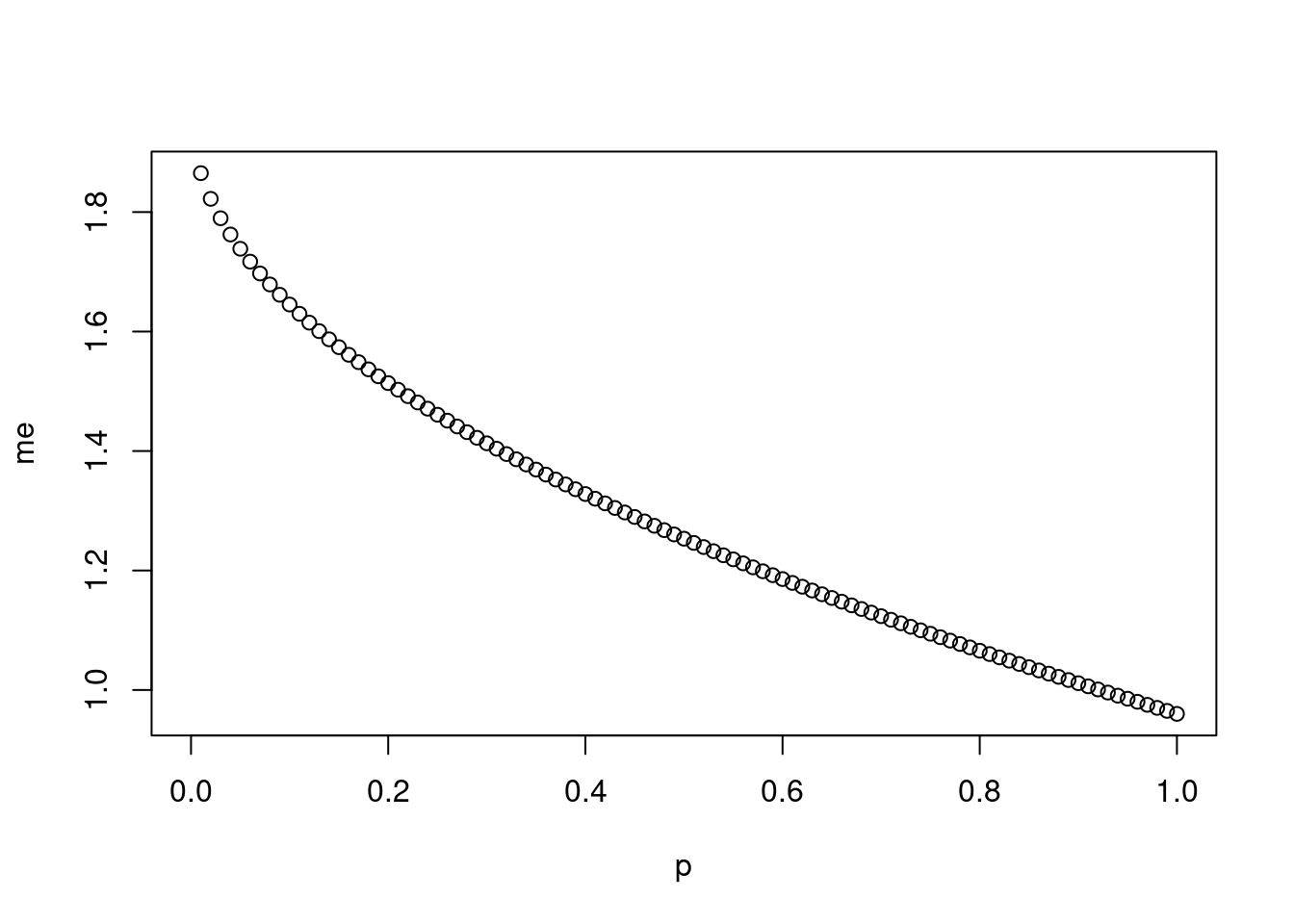
Imagine you’ve set out to survey 1000 people on two questions: are you female? and are you left-handed? Since both of these sample proportions were calculated from the same sample size, they should have the same margin of error, right? Wrong! While the margin of error does change with sample size, it is also affected by the proportion.
The first step is to make a vector
pthat is a sequence from 0 to 1 with each number separated by 0.01:We then create a vector of the margin of error (
me) associated with each of these values ofpusing the familiar approximate formula (ME = 2 X SE):## Warning in sqrt(p - (1 - p)/n): NaNs producedFinally, plot the two vectors against each other to reveal their relationship:
Probability
Simulating a coin flip with
sample():The code above simulates 100 flips of a fair coin.
Add different probability with
The sample can also be saved as a vector for further analysis (such as calculating the mean, or other statistics)
For loops, bootstrapping, and inference
The for loop is a cornerstone of computer programming. The idea behind the for loop is iteration: it allows you to execute code as many times as you want without having to type out every iteration.
Example for loop (from DataCamp data analysis and statistical inference course, also see Verzani simpleR p.48):
In this example, we want to iterate the two lines of code inside the curly braces that take a random sample of size 50 from area then save the mean of that sample into the sample means50 vector. Without the for loop, this would be painful:
sample_means50 <- rep(NA, 5000) samp <- sample(area, 50) sample_means50[1] <- mean(samp) samp <- sample(area, 50) sample_means50[2] <- mean(samp) samp <- sample(area, 50) sample_means50[3] <- mean(samp) samp <- sample(area, 50) sample_means50[4] <- mean(samp)and so on… With the for loop, these thousands of lines of code are compressed into a handful of lines:
# The 'ames' data frame and 'area' and 'price' objects are already loaded # Set up an empty vector of 5000 NAs to store sample means: sample_means50 = rep(NA, 5000) # Take 5000 samples of size 50 of 'area' and store in 'sample_means50'. # Also print 'i' (the index counter): for (i in 1:5000) { samp = sample(area, 50) sample_means50[i] = mean(samp) print(i) }In the first line we initialize a vector. In this case, we created a vector of 5000 NAs called
sample means50. This vector will store values generated within the for loop. NA means not available, and in this case they’re used as placeholders until we fill in the values with actual sample means. NA is also often used for missing data in R.The second line calls the for loop itself. The syntax can be loosely read as, ‘for every element
ifrom 1 to 5000, run the following lines of code’. You can think ofias the counter that keeps track of which loop you’re on. Therefore, more precisely, the loop will run once wheni=1, then once wheni=2, and so on up toi=5000.The body of the for loop is the part inside the curly braces, and this set of code is run for each value of
i. Here, on every loop, we take a random sample of size 50 fromarea(note: the sample size can be previously defined by creating a vector), take its mean, and store it as the ith element ofsample_means50. In order to display that this is really happening, we asked R to printiat each iteration. This line of code is optional and is only used for displaying what’s going on while the for loop is running.The for loop allows us to not just run the code 5000 times, but to neatly package the results, element by element, into the empty vector that we initialized at the outset. You can also run multiple distributions through the same for loop:
# The 'ames' data frame and 'area' and 'price' objects are already loaded # Initialize the sample distributions: sample_means10 = rep(NA, 5000) sample_means100 = rep(NA, 5000) # Run the for loop: for (i in 1:5000) { samp = sample(area, 10) sample_means10[i] = mean(samp) samp = sample(area, 100) sample_means100[i] = mean(samp) }Don’t worry about the fact that
sampis used for the name of two different objects. In the second command of the for loop, the mean ofsampis saved to the relevant place in the vectorsample_means10. With the mean saved, we’re now free to overwrite the object samp with a new sample, this time of size 100. In general, anytime you create an object using a name that is already in use, the old object will get replaced with the new one, i.e. R will write over the existing object with the new one, which is something you want to be careful about if you don’t intend to do so.’Another example: Obtain a random sample, calculate the sample’s mean and standard deviation, use these statistics to calculate a confidence interval, repeat steps (1)-(3) 50 times.
For loops can also be used for bootstrapping.
Bootstrapping is a way of amplifying your data for estimation.
Definition (from Google):
a technique of loading a program into a computer by means of a few initial instructions that enable the introduction of the rest of the program from an input device.
There is also a
bootpackage available for RSampling vs. bootstrapping: The sampling distribution is calculated by resampling from the population, the bootstrap distribution is calculated by resampling from the sample.
Example: bootstrap confidence interval for the average weight gained by all mothers during pregnancy. (From Datacamp data analysis and statistical inference course lab 4)
The inference function
Writing a for loop every time you want to calculate a bootstrap interval or run a randomization test is cumbersome. This is a custom function that automates the process. By default the
inferencefunction takes 10,000 bootstrap samples (instead of the 100 you’ve taken above), creates a bootstrap distribution, and calculates the confidence interval, using the percentile method.Example
# The 'nc' data frame is already loaded into the workspace # Load the 'inference' function: load(url('http://s3.amazonaws.com/assets.datacamp.com/course/dasi/inference.Rdata')) # Run the inference function: inference(nc$gained, type='ci', method='simulation', conflevel=0.9, est='mean', boot_method='perc' )method='se'will perform the method based on the standard errorest='median'will create an interval for the median instead of the mean
Example (Datacamp data analysis and statistical inference course lab 4):
use the inference function for evaluating whether there is a difference between the average birth weights of babies born to smoker and non-smoker mothers:
# The 'nc' data frame is already loaded into the workspace inference(y = nc$weight, x = nc$habit, est = 'mean', type = 'ci', null = 0, alternative = 'twosided', method = 'theoretical', order=c('smoker','nonsmoker') )The first argument is y, which is the response variable that we are interested in:
nc$weight.The second argument is the grouping variable
x, which is the explanatory variable multiplied by the grouping variable across the levels of which we’re comparing the average value for the response variable, smokers and non-smokers:nc$habit.The third argument
estis the parameter we’re interested in: ‘mean’ (other options are ‘median’, or ‘proportion’.)Next we decide on the type of inference we want: a hypothesis test (‘ht’) or a confidence interval(‘ci’).
When performing a hypothesis test, we also need to supply the null value, which in this case is 0, since the null hypothesis sets the two population means equal to each other.
The alternative hypothesis can be ‘less’, ‘greater’, or ‘twosided’.
The method of inference can be ‘theoretical’ or ‘simulation’ based.
The order function changes the order of the variable levels.
You can also add
success=, which defines a success for survey data-type questions.Another example:
Take a subset
spainofatheismwith only the respondents from Spain. Calculate the proportion of atheists within this subset. Use theinferencefunction on this subset, grouping them by year. (From Datacamp data analysis and statistical inference course lab 4)# Take the 'spain' subset: spain = subset(atheism, atheism$nationality == 'Spain') # Calculate the proportion of atheists from the 'spain' subset: proportion = nrow(subset(spain,response == 'atheist'))/nrow(spain) # Use the inference function: inference(spain$response, spain$year, est = 'proportion', type = 'ci', method = 'theoretical', success = 'atheist' )
T-test
t.test(y~x, var.equal = TRUE)
# when both variables are numeric
t.test(y1,y2, var.equal = TRUE)
# one-sample t-test, with null hypothesis mean mu=3.
t.test(y,mu=2, var.equal = TRUE)
# paired t-test
t.test(y~x, paired=TRUE, var.equal = TRUE)
# one-tailed t-test
t.test(y~x, alternative = 'less', var.equal = TRUE)
# one-tailed t-test
t.test(y~x, alternative = 'greater', var.equal = TRUE)- Default t-test assumes heterogeneity of variance and applies a
Welch/Satterthwaite df modification. Include
var.equal = TRUEto indicate homogeneity of variance. - Nonparametric and resampling alternatives to t-tests are available.
- Also see
- Quick-R
- Verzani simpleR p.63
- T-tests Columbia
- CPSC 440 Lecture Notes Chapter 06 p.16
- CPSC 440 lab 07 notes p.5
T-test assumptions
Normality
Shapiro-Wilk W test (W>0.9 desired, see flowchart from PATH 591 lecture 03 p.11 in linear regression section):
Normal quantile-quantile plot
- Note that ggplot2 does not have features for easy creation of q-q plots.
Linear regression
See R in action ch.8.
Model syntax and functions
See R in Action tables 8.2 and 8.3 for full syntax info.
Linear regression formula symbols. Adapted from R in Action.
~: dependent variable on left, independent variables on right, likey~a+b. -+: Separates independent variables.:Interaction, such asy~a:b, meaning interaction of independent variables a and b.*: All possible combinations of the variables.^: Restricts interactions to a certain degree. The formulay ~ (a + b + c)^2would be read by R as y ~ a + b + c + a:b + a:c + b:c..: References all independent variables in the data frame.-: Subtracts a variable from the model.-1: Suppresses the intercept.I(): Allows use of arithmetic within the parentheses.
Linear regression functions that can be used after specifying the model. Adapted from R in Action.
aic()orbic(): Prints Aikake’s or Bayes’ Information Criterion.anova(): ANOVA table.coefficients(): Shows intercept and slopes for the regression model.confint(): Confidence intervals (95 percent by default).fitted(): Lists predicted values.plot(): Plots for evaluating model fit. To select specific plots, add ‘which=’.residuals(): Residuals are basically the deviation from the model fit.rstandard()for standardized residuals (divided by standard deviation, fitted including the current data point).rstudent()for studentized residuals (divided by standard deviation, but fitted ignoring the current data point).Stdres()andstudres()can also be used but require the MASS package (Modern Applied Statistics with S).See PATH 591 lecture 03 for a clear visual explanation of residuals.
 Visual explanation of residuals from PATH 591 lecture 03 p.1
Visual explanation of residuals from PATH 591 lecture 03 p.1
summary(): Summary of the regression model. To view a specific part, such as just the R2, add$r.squaredor$adj.r.squaredvcov(): Lists the covariance matrix for model parameters.
Selection of regression models
- Begin with full model
- Hierarchical elimination of variables in multiple linear regression: eliminate non-significant variables from the full model, or until there is no further improvement in the adjusted r2.
- Information criteria, such as Akaike’s Information Criterion (AIC) or Bayes Information Criterion (BIC), can be used to select models and covariance stuctures. These criteria rate linear models based on fit and model size. The model with the lowest AIC and/or BIC has the best balance between fit and model size.
- Further information:
- R in Action 8.6
- Linear Models with R 8.3
- CPSC 542 Lecture 10 pp. 4-7
Linear regression assumptions
Normality of residuals
Shapiro-Wilk W statistic: based on mathematics of normal probability plots. Compares variance of distribution to variance expected under normal distribution. Shapiro-Wilk W statistic trumps p value. Normality testing workflow from PATH 591 lecture 03 p.11:
 Normality testing workflow from PATH 591 lecture 03 p.11
Normality testing workflow from PATH 591 lecture 03 p.11- Make sure you are testing residuals and not raw data. It is acceptable to test normality using studentized residuals.
- See SAS for mixed models section 10.2.3 p.418, and ‘Linear Mixed Models: A Practical Guide Using Statistical Software’ by West Welch and Galecki p.105.
Graphical evaluation by normal quantile-quantile plot
Skewness: measure of asymmetry in distribution. A perfect normal distribution has skewness=0. Positively skewed distributions=tail to the right, negatively skewed=tail to the left.
Kurtosis: another measure of asymmetry in distribution. Leptokurtic distributions (kurtosis<0) will have more observations at the center, platykurtic distributions (kurtosis>0) are spread evenly.
Independence of residuals
- Serial correlation: Durbin-Watson D.
- Found in the
carandlmtestpackages. - Use
acf(lm_name$residuals),acf(rstudent(lm_name)), oracf(studres(lm_name)). studres(in the MASS package) will produce an autocorrelation plot. The dashed lines indicate the 95% confidence interval, and correlations ideally lie within the lines.
- Found in the
Homogeneity of residual variances
- Plots of residuals vs. fitted/predicted values, residuals vs. any independent variable (dot or box plots); absolute value or square root of absolute value of residuals vs. fitted values.
- Plots of residuals vs predicted values in datasets with HOV would look like a cloud/ball with no correlation. If the plot looks like a megaphone, it suggests a missing term in the model (see ‘strategies to address model violations’ below), or the need to use an unstructured covariance model.
- Residuals should also sum to zero
- Spearman rank order correlation between the absolute values of the residuals and the predicted values
- See below under ‘Variance assessment for multivariate, factorial, and repeated measures designs’ for information on how to assess HOV in complex designs using fit statistics like aic() and bic().
Linearity and additivity
- Linearity and additivity of the relationship between dependent and independent variables.
- Assessed with graphical evaluation by plot of residuals vs predicted values.
Lack of influential observations
Cook’s D is a distance statistic that measures change in regression parameter estimates when an observation is deleted.
- Cook’s D values are sometimes compared with a critical F value F0.50(k,n-k-1) (see PATH 591 lecture 03 p.15).
- According to R in Action 8.4.3, Cook’s D values greater than 4/(n-k-1), where n is the sample size and k is the number of predictor variables, indicate influential observations, but 1 can also be an appropriate cutoff.
A Bonferroni outlier test can also be performed with the
outlierTest()function in thecarpackage.Plots of Cook’s D values and residuals vs leverage allow graphical assessment of influential observations. Add a critical line to the Cook’s Distance plot with:
Global validation of linear model assumptions with the
gvlma package
- This is a new and improved approach to validating the assumptions of
linear models.
- Normally, individual tests for specific assumptions are performed. This increases the type I error rate and masks combinatorial effects of multiple assumption violations (results of one assumption test may be impacted by violations of other assumptions).
- Assessment by graphical methods is subjective.
- gvlma provides an integrated global test of all four major assumptions (normality of residuals, independence of residuals, homogeneity of residual variances, linearity) that controls type I error rate, and also provides several plots.
gvlmareturns five summary values:- Global stat: combination of the statistics for skewness, kurtosis, link function, and heteroscedasticity, representing the global test of all model assumptions.
- Skewness
- Kurtosis
- Link Function: the link function is a feature of all linear models that links the linear model to the mean of the response variable. ‘Identity’ is the link function for a normal distribution. A misspecified link function, meaning that the link function does not match the distribution of the data, will result in a large and significant value for this statistic.
- Heteroscedasticity: tests the assumption of homogeneity of residual variances.
- Further information:
- Peña EA, Slate EH. Global Validation of Linear Model Assumptions. J. Am. Stat. Assoc. 101:341 (2006). doi: 10.1198/016214505000000637.
- R in Action 8.3, 13, and Quick-R regression diagnostics.
- PATH 591 lecture 03
Strategies for addressing model violations
- It is not appropriate to simply throw out influential data points unless they are due to measurement error or some other problem.
- Addition of variables to the model to account for residual variance
- Transformation of independent or dependent variable
- Normalizing transformations (+1 used to avoid undefined values for
zeros, log(0+1)=1)
- Log: log(y+1) (usually log10 but can also be log2 or loge/ln)
- Square root:
- Reciprocal: 1/(y+1) (particularly effective at reducing skewness)
- See PATH 591 lecture 03 pp.11-15.
- Variance-stabilizing transformations
- Square root, log, reciprocal (in order of increasing heterogeneity of variance)
- Linearizing transformations for curvilinear relationships
- Exponential function: linearized by log transformation of y
- Logarithmic function: linearized by log transformation of x
- Power function: linearized by log transformation of both x and y
- See PATH 591 lecture 04 C
- Arcsin(y) can correct non-normality or heteroscedasticity for variables that are proportions (1-100%). See PATH 591 problem set 4.
- The independent variable can also be transformed if it is continuous. Categorical independent variables should not be transformed.
- Normalizing transformations (+1 used to avoid undefined values for
zeros, log(0+1)=1)
- The Spearman rank order correlation between the independent and dependent variable is another type of correlation that is more widely valid, especially in situations where F test assumptions are violated.
- Curvilinearity in a plot of resids vs. preds can be addressed by fitting a polynomial regression function.
- Weighted least squares regression can be used to address serial correlation or influential observations. See PATH 591 lecture 03 p.14. It allows influential observations to be re-weighted to minimize interference with the model. SAS provides a ‘reweight’ statement for this purpose.
- Link function violations: as with violations of other assumptions, transformation of the data set, addition of variables to the model, or use of a different model may be necessary. Different link functions, such as binomial or Poisson, can usually be specified with a generalized linear mixed models approach. If a simple correlation is desired, the Spearman test can be used instead.
Reporting regression results
F0.05(k, n-1 df)=, r2, p<
This information is usually adequate for publication purposes. See PATH 591 lecture 04 A p.8.
ANOVA
ANOVA is a type of linear regression analysis with categorical independent variables. R in Action ch.9 contains an excellent section on ANOVA.
ANOVA model syntax and functions
Options for basic ANOVA:
aov(model, data=data.frame)lm()anova()glm()
See R in Action table 9.5 for more syntax info and model examples.
- Model syntax is similar to linear regression model syntax.
- A regression approach with the
lm()function is more flexible than a basic ANOVA analysis with theaov()function. It allows inclusion of both categorical and quantitative independent variables and enables prediction. - The
aov()function uses Type I sums of squares, which is not appropriate for imbalanced designs (groups of different sizes). TheAnova()function (with a capital A) in thecarpackage allows use of Type II or III sums of squares. - The order of terms in the model can sometimes influence the result
in certain situations, such as imbalanced designs and designs including
covariates. It may also depend on how the variance is partitioned (Type
I-III sums of squares). See CRAN
7.18.
- Note on Type III sums of squares from Muenchen R for SAS and SPSS users 23.12 p.431: > The R community has a very strongly held belief that tests based on partial sums of squares can be misleading. One problem with them is that they test the main effect after supposedly partialing out significant interactions. In many circumstances, that does not make much sense. See the paper, Exegesis on Linear Models, by W.N. Venables, for details [39].
glm()uses iteratively reweighted least squares (IWLS). Further information in R in Action chapter 13.- If the model contains categorical variables with >2 levels, R creates ‘indicator’ or dummy variables for each level.
ANOVA assumptions
Normality of residuals
Shapiro-Wilk W test (W>0.9 desired, see flowchart from PATH 591 lecture 03 p.11 in linear regression section):
Normal quantile-quantile plot
Homogeneity of residual variances
Bartlett test:
bartlett.test(). Bartlett test is sensitive to deviations from normality.Levene test
Brown-Forsythe test
- The Brown-Forsythe test evaluates deviations from group medians, and thus is robust to violations of normality.
These HOV tests are only appropriate for one-way designs. A different approach is required for more complex designs.
Factorial designs can be converted to one-way by splitting each treatment combination into a separate group and identifying it as a single level in one independent variable, calling the one new independent variable ‘treatment,’ and then performing the Brown-Forsythe test. This does not work for repeated measures data because values for each group at one timepoint are correlated to values at other timepoints.
Variance assessment for multivariate, factorial, and repeated measures designs
- Graphical assessment as described for linear regression above:
- Plot of residuals vs predicted values
- Plot of residuals vs independent variables (dot or box plots)
- Numerical assessment using fit statistics
I am more familiar with this in SAS. Explanation below.
In general, you want to use the simplest model possible that minimizes AIC, AICC, and BIC while still meeting the assumptions of the model. Mind the assumptions of each covariance structure. See CPSC 542 Lecture 10 pp. 4-7.
Donald Bullock (Illinois CPSC statistics professor):
You select an error structure with heterogeneous variances [like unstructured] and compare that to a model with everything the same with the exception of homogeneous variances [like compound symmetry]. The differences in the log likelihoods will be a chi-square with degrees of freedom equal to the differences in the number of estimates in the two models.
This is also described in the Littell ‘SAS for mixed models’ text p. 172.
In other words, run the code using the unstructured model, and copy/paste the ‘Fit Statistics’ table and the number of covariance parameter estimates into Excel. The number of estimates (also called covariance parameters) is given under ‘Dimensions’ in the output. Also look at the ‘-2 Res Log Likelihood’ number under ‘Fit Statistics’ in the output.
Then run the code several more times, using different covariance structures each time (cs, ar(1), arh(1), toep, and toeph), and paste the fit statistics and estimates into excel also. Then, for each test other than unstructured, type =chidist(x, df), using the difference between the ‘-2 Res Log Likelihood’ for unstructured and the other test as the ‘x’ or chi square, and the difference in #parameters between unstructured and the other test as the df.
The answer will be a p value. A significant p indicates that the unstructured model provides superior fit.
- Graphical assessment as described for linear regression above:
Independence of residuals
Independence of residuals is required. Any pairing in the data, such as in repeated measures designs, must be appropriately specified in the model.
ANOVA multiple comparisons
All pairwise comparisons
or
Specific pairwise comparisons with contrasts and estimates
- This is similar to the estimate capability in SAS PROC MIXED and
GLIMMIX. Also see R in Action 9.4, Linear Models with R p.180.
Download and install the
multcomppackage.First, print the covariance matrix with
model.matrix(model_name)to identify coefficients for contrasts.Next, use the numbers from error matrix to indicate group comparisons of interest.
ANOVA Interaction effects
Options for creation of interaction plots:
Covariates and repeated measures
Using aov() or lm() is the simplest method,
but also the least flexible. It assumes sphericity, and thus is not
suitable for most real-world datasets. A mixed models approach is
required to appropriately model covariance. R in Action does not cover
mixed models in depth.
A few options:
Anova()in thecarpackagelmer()in thelme4package. See CRAN 7.35 for discussion of p values in this function.lme()orgls()in thenlmepackage
Analysis of covariance includes both fixed effects (independent variables) and random effects (covariates included to model random variation). If the effect can be reproduced, it’s fixed. With fixed effects you are interested in the means, but with random effects you are interested in variances. Blocks could be either fixed or random; for example, if you are doing a test on trees and you want to block for forest, setting blocks as random would indicate that you want to block for just all forests everywhere in general and these forests are representative of all forests, whereas setting blocks as fixed would indicate that you want to block for these specific forests you’re evaluating. See CPSC 440 Lecture Notes Chapter 08 ANOVA.
The covariance structure must be appropriately
specified. Fit statistics and information criteria can be used
to identify an appropriate covariance structure:
AIC(model). See ‘Selection of regression models’ in the
Linear regression section, and ‘Variance assessment for multivariate,
factorial, and repeated measures designs’ in the ANOVA section
above.
Non-parametric tests
Fisher’s exact test
Useful when both dependent and independent variables are categorical, or when dependent variable is a count.
It evaluates the association, or contingency, between two kinds of classifications.
Data must first be put into a contingency table:
Next, run the test and reference the table
See R in action ch. 7.2, Crawley The R Book ch. 14-15, UCSC R tips.
Example from my grad school lab: Prostate cancer incidence data from TRAMP Tomato Soy paper
- Zuniga KE, Clinton SK, Erdman JW. The interactions of dietary tomato powder and soy germ on prostate carcinogenesis in the TRAMP model. Cancer Prev. Res. (2013). DOI: 10.1158/1940-6207.CAPR-12-0443
- Code located in R-sample-code/fishers-exact.
Wilcoxon rank-sum
- Also known as the Mann-Whitney U test
- Used to compare two non-parametric independent samples
- Note that, although the Wilcoxon rank sum test does not require normality, it does require homogeneity of variances and independence of random samples.
- See R in Action 7.5
Wilcoxon signed rank
- Used to compare two non-parametric paired samples
- See R in Action 7.5, Verzani simpleR p.67
Kruskal-Wallis
Non-parametric one-way ANOVA, where y is a dependent
variable and a is a categorical independent variable with
≥2 levels.
Kruskal-Wallis assumptions
Non-normality
A non-parametric Kruskal-Wallis test is used when data fail the assumption of normality, and are not amenable to transformation. It is still worthwhile to perform the usual normality testing to demonstrate this.
Homogeneity of variances
HOV is still required. Use a test that is not affected by non-normality, such as Brown-Forsythe.
Kruskal-Wallis multiple comparisons post-hoc tests
Pairwise Wilcoxon testing
This function allows control of the experiment-wide error rate and is the best non-parametric multiple comparisons method available in R.
Adjustment options:
holmhochberghommelbonferroniBHBYfdrnone
From R Documentation:
The first four methods are designed to give strong control of the family-wise error rate. There seems no reason to use the unmodified Bonferroni correction because it is dominated by Holm’s method, which is also valid under arbitrary assumptions.
Nemenyi test
- Requires the
PMCMRpluspackage (Pairwise Multiple Comparisons of Mean Rank Sums). Note that the originalPMCMRpackage has been deprecated.
npmc package
There used to be an npmc package that is referred to in some documentation. It has been deprecated.
Friedman
- where
yis the numeric outcome variable,Ais a grouping variable, andBis a blocking variable that identifies matched observations. In both cases,datais an option argument specifying a matrix or data frame containing the variables. - Useful for non-parametric non-independent data with ≥2 groups (such as repeated measures designs).
- May only be valid with balanced designs.
Non-parametric factorial datasets
Try the nlme, MultNonParam,
npmlreg, or nparLD packages.
Power analysis
See R in Action ch.10
Principal Component Analysis
See R in Action ch.14
Bioconductor
Bioconductor is a repository of R packages for bioinformatic analysis.
Basics
Install core packages (run the commands sequentially). These commands can also be used to update packages.
Install specific packages:
Troubleshoot installations to flag packages that are either out-of-date or too new for your version of Bioconductor. The output suggests ways to solve identified problems, and the help page
?biocValidlists arguments influencing the behavior of the function.
ddCt
The ddCt package for Bioconductor performs automated ΔΔCt calculations on qPCR data. Install with
It seems to require a very specific format for the files output from SDS, and I was not able to get it to work with my data. It would be far easier to create a VBA macro in Excel.
ppiStats
- ppiStats calculates summary statistics and makes graphs for AP-MS or hybrid assay data. Not very useful.
Proteomics
- I walked through the ‘Mass spectrometry and proteomics data analysis’ workflow in 2014. Running the code (at least all at once) was only partially successful.
Plots
Helpful resources for plotting
- R in Action
- R Graphics Cookbook by Winston Chang (mostly for ggplot2). CC0 1.0 license (public domain dedication, no copyright).
Base graphics
Plot types
Scatterplots:
plot(x=,y=,options)If your data frame only has two variables, you only need to specify the data frame:
plot(data.frame)To select specific variables from a data frame to display on the graph, use
plot(x=data.frame$variable, y= data.frame$variable)Line chart:
plot(x,y,type='l')Plotting >2 variables:
plot(data.frame[rows,columns])Boxplot:
boxplot()See the multiple comparisons ANOVA section above
Plotting one variable as a function of another is very similar to creating a linear model:
boxplot(y ~ a)- As usual, if you
attach()the dataset you do not need to specify the data frame name here. - I found base graphics actually work better for boxplots than ggplot2.
- As usual, if you
New variables can also be calculated and plotted even if they are not in the original data frame:
Setting line widths for individual parts of the boxplot:
- box outline:
lwd= - median line:
medlwd= - outlier points:
outlwd=
- box outline:
Adding symbols for group means:
After creating the boxplot, create a new vector and use the
aggregate()function: `means <- aggregate(model, data.frame, mean)Next, create a separate
points()function:Note that, as with other functions in R, variables will be sorted alphabetically or numerically. To change the order, you must create a separate vector and use
order()orfactor()to specify the order. See the section on data frames above, and previous code.
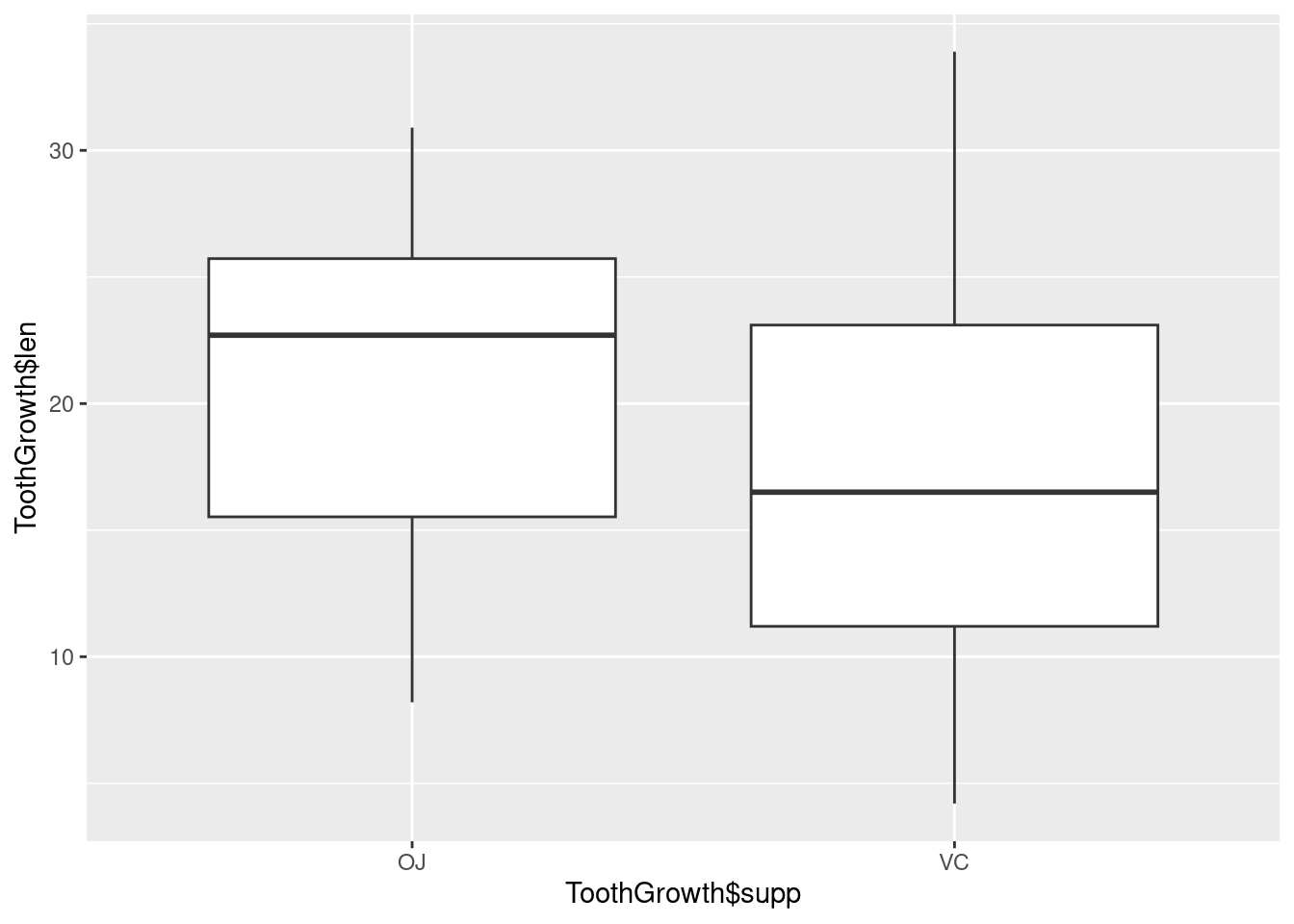
Plotting factorial datasets: Sample code from the R Graphics Cookbook ch.2 ‘Creating a box plot’.
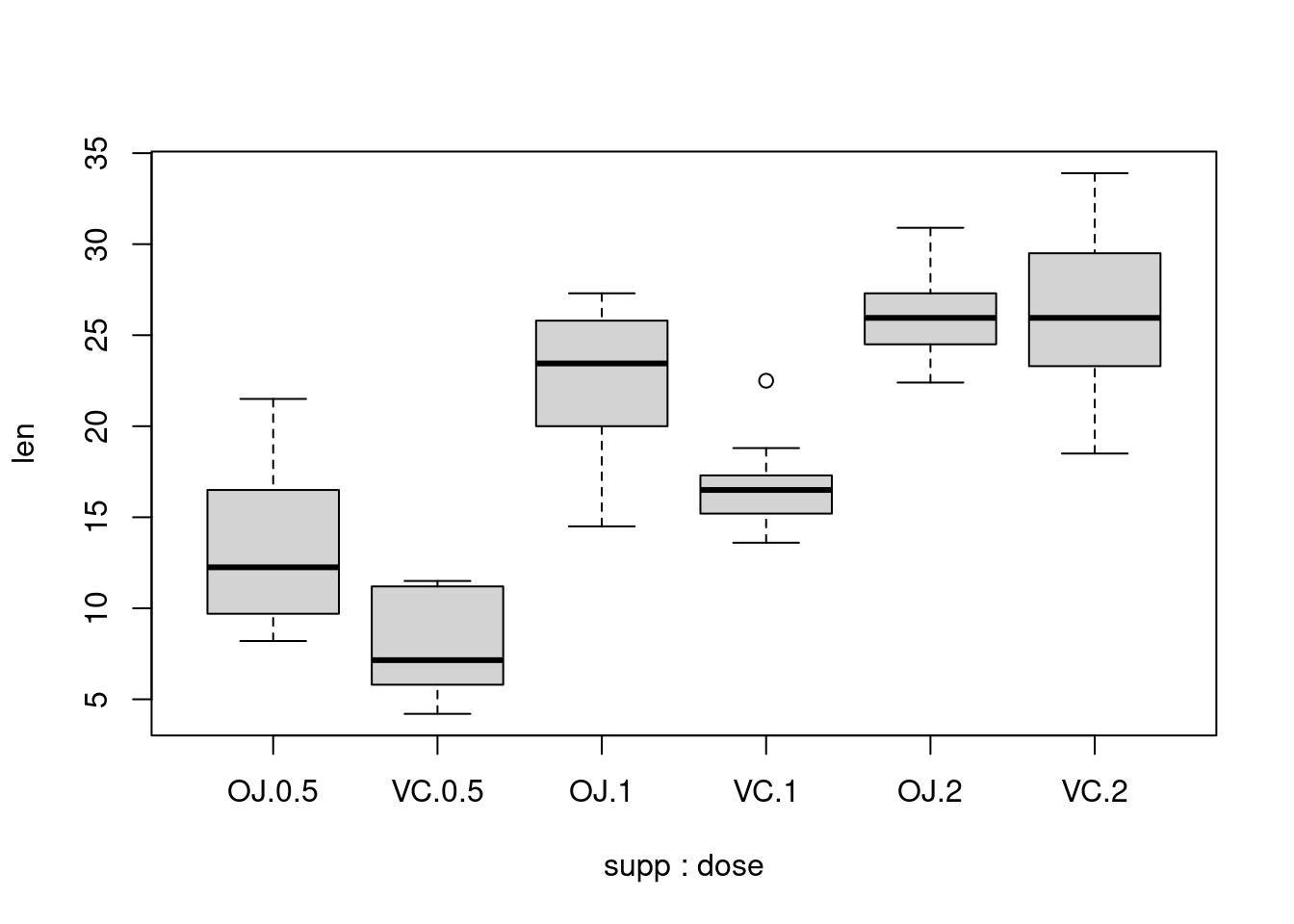
With the ggplot2 package, you can get a similar result using qplot() (Figure 2-11), with geom=‘boxplot’:
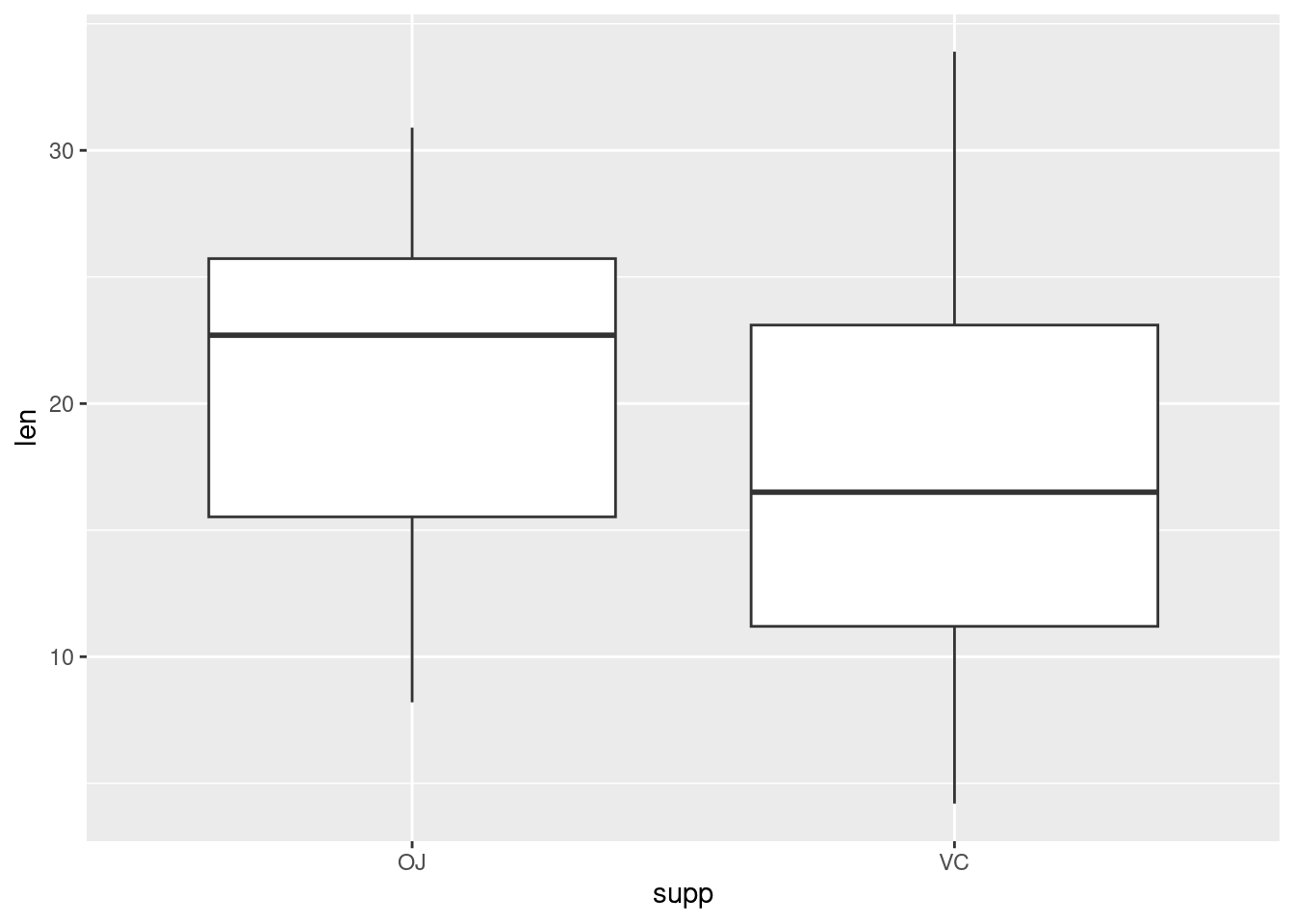
If the two vectors are already in the same data frame, you can use the following syntax:
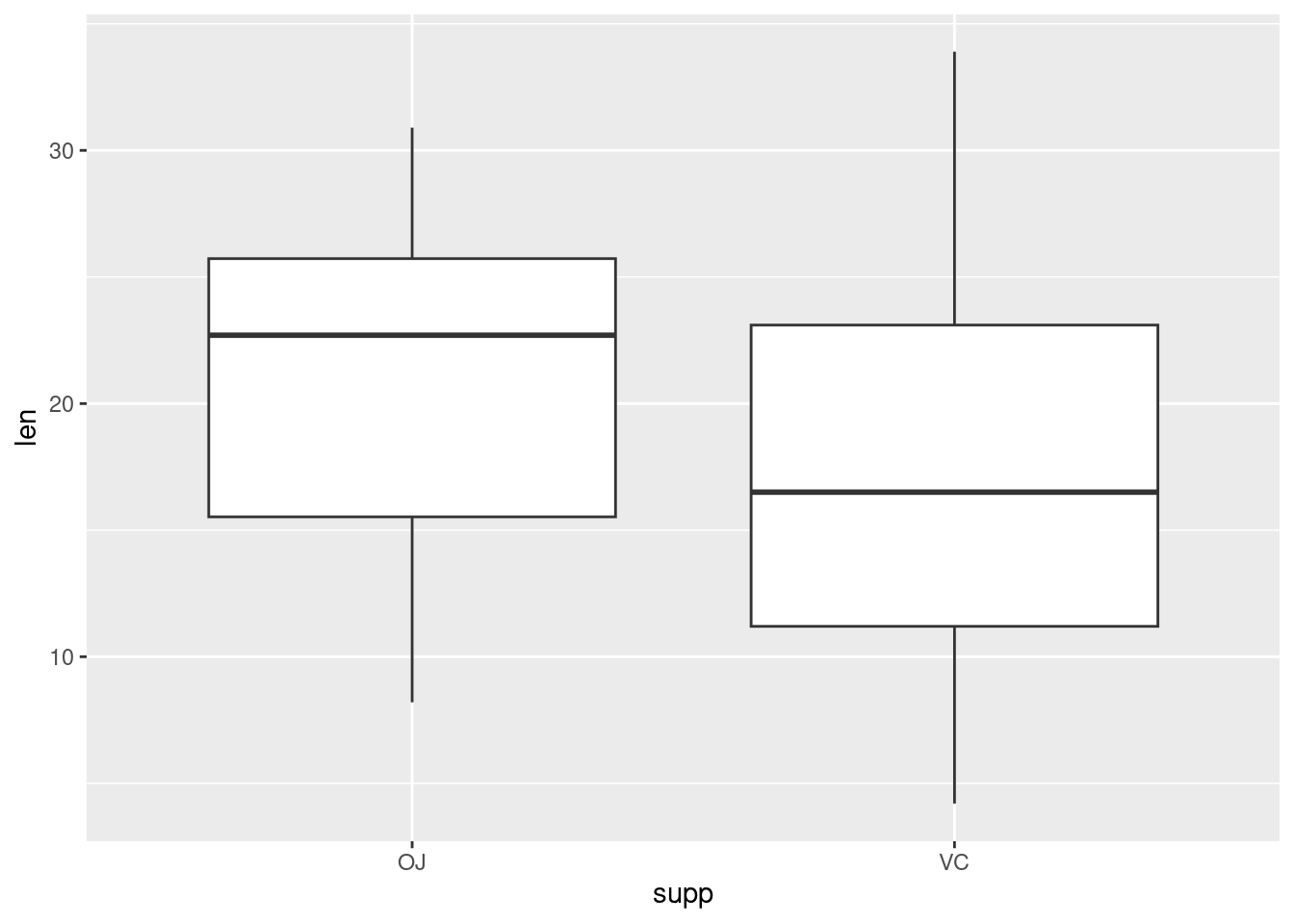
This is equivalent to:
It’s also possible to make box plots for multiple variables, by combining the variables with interaction(), as in Figure 2-11. In this case, the dose variable is numeric, so we must convert it to a factor to use it as a grouping variable:
# Using three separate vectors qplot(interaction(ToothGrowth$supp, ToothGrowth$dose), ToothGrowth$len, geom = 'boxplot')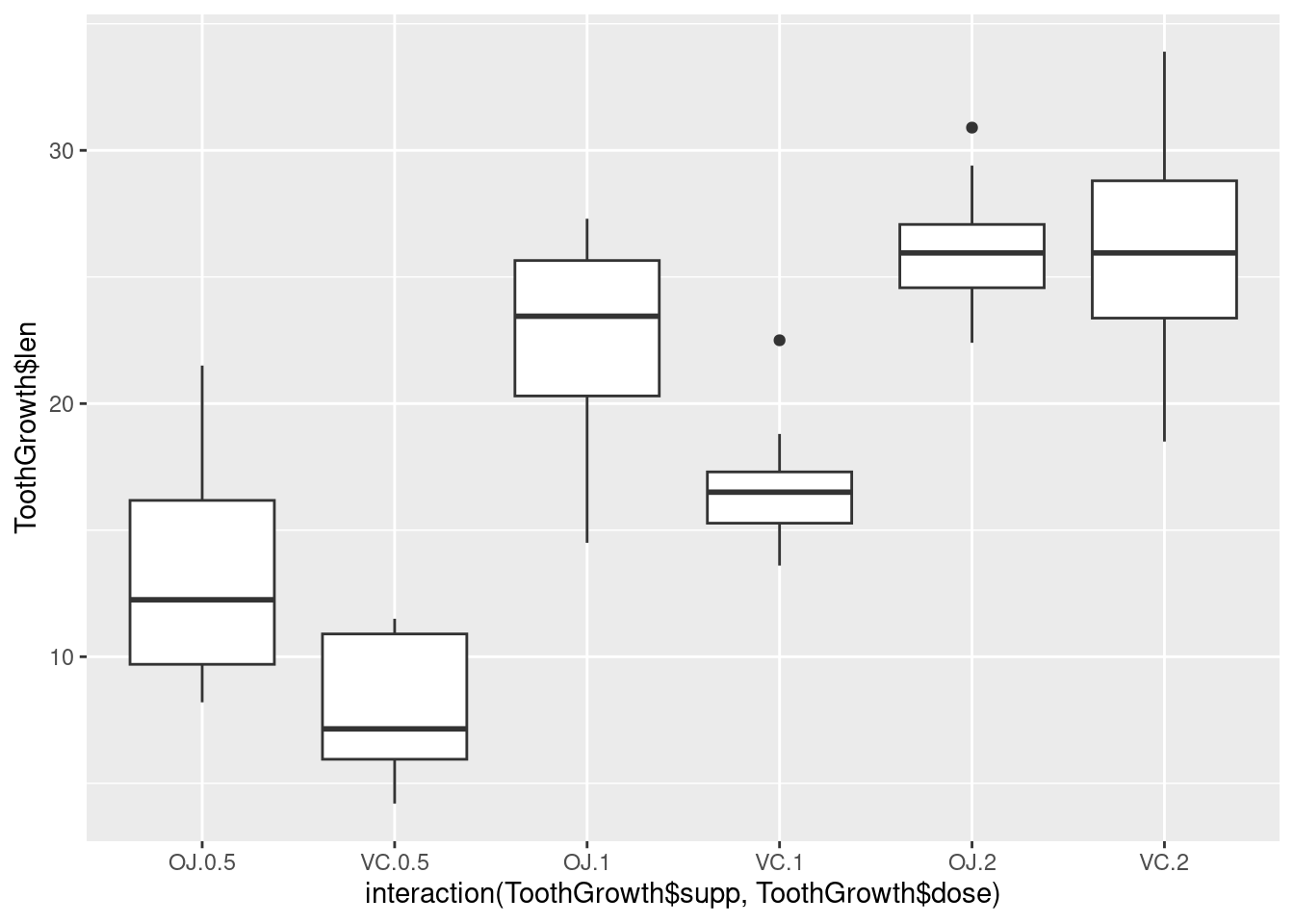
Alternatively, get the columns from the data frame:
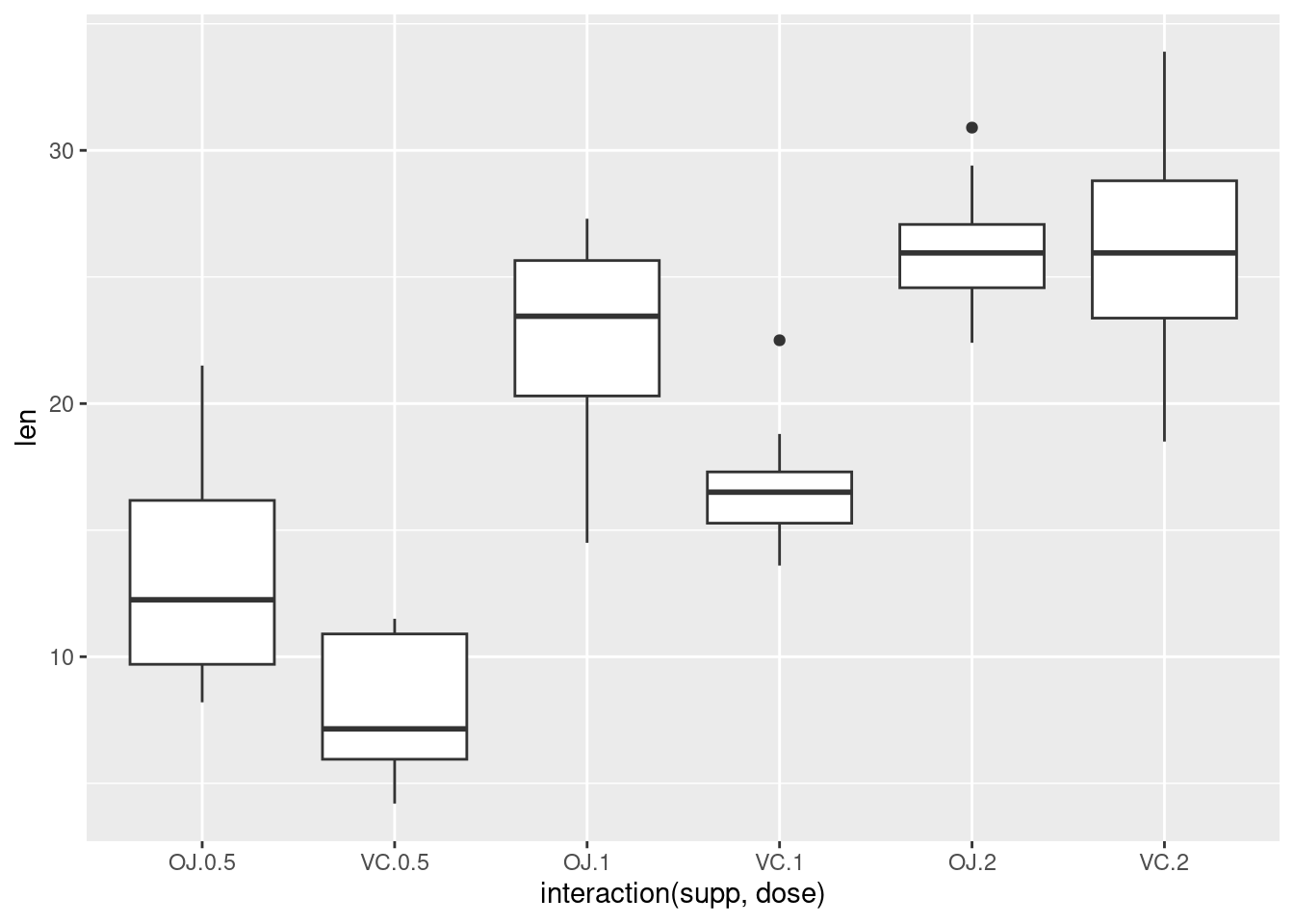
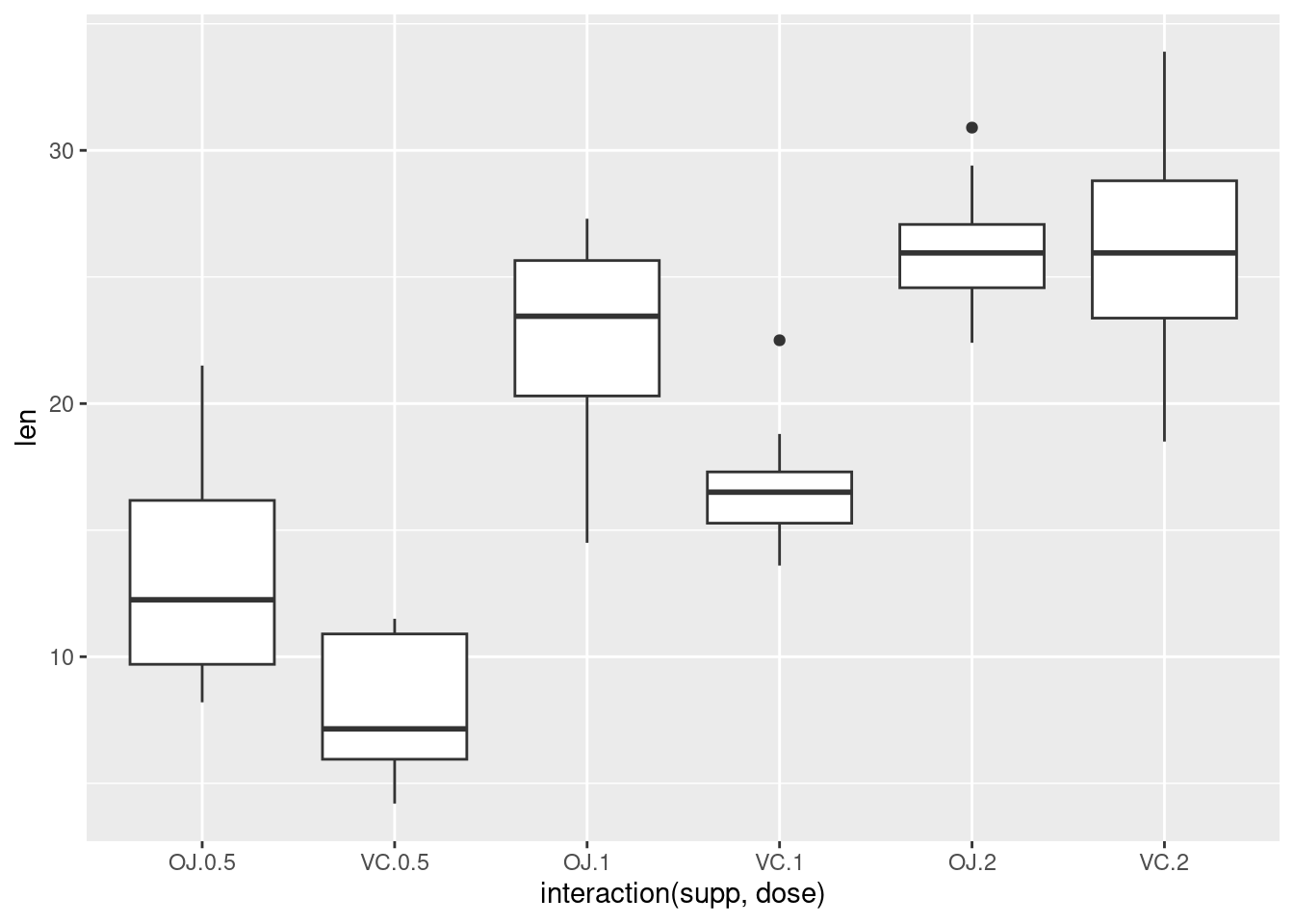
This is equivalent to:
Dot plot
- See R Graphics Cookbook Ch. 6.
- Can make dot plots with box plots underlaid or alongside using ggplot2.
Histogram:
hist()Histograms are useful for inspecting the distribution of the dataset.
To control histogram divisions and limits of x axis:
Combined boxplot and histogram:
simple.hist.and.boxplot()Bar chart:
barplot()- You can nest the creation of a table into the barplot function: `barplot(table(data.frame$variable))
Pie chart:
pie(data.frame)Mosaic plot (useful for showing how different categories are related):
Volcano plots
Graphical parameters
See Quick-R, and of course R in Action, for thorough documentation.
Many graphical options are specified with the
par()function.- Size of text and symbols:
cex= - Symbol style:
pch= - Line type:
lty= - Line width:
lwd=
- Size of text and symbols:
Colors
Colors can be specified by index number, name, hexadecimal, or RGB.
See Earl Glynn’s color chart for a visual listing of colors in R by index number.
 R colors
R colorsView all available color names:
color()The basic palette consists of 8 colors. Other color vectors with n contiguous colors can be created with
gray(n),rainbow(n),heat.colors(n),terrain.colors(n),topo.colors(n), andcm.colors(n).The
RColorBrewerpackage can also be used for color palettes. See website for more info.To make palettes available in R:
palette.name <- brewer.pal(n, 'name'). Next, when selecting a color palette for a chart, use the vector name (palette.namein this example).There are 3 types of palettes, sequential, diverging, and qualitative.
- Sequential palettes are suited to ordered data that progress from low to high. Lightness steps dominate the look of these schemes, with light colors for low data values to dark colors for high data values. The sequential palette names are: Blues BuGn BuPu GnBu Greens Greys Oranges OrRd PuBu PuBuGn PuRd Purples RdPu Reds YlGn YlGnBu YlOrBr YlOrRd. All the sequential palettes are available in variations from 3 different values up to 9 different values.
- Diverging palettes put equal emphasis on mid-range critical values and extremes at both ends of the data range. The critical class or break in the middle of the legend is emphasized with light colors and low and high extremes are emphasized with dark colors that have contrasting hues. The diverging palettes are BrBG PiYG PRGn PuOr RdBu RdGy RdYlBu RdYlGn Spectral. All the diverging palettes are available in variations from 3 different values up to 11 different values.
- Qualitative palettes do not imply magnitude differences between legend classes, and hues are used to create the primary visual differences between classes. Qualitative schemes are best suited to representing nominal or categorical data. The qualitative palettes are: Accent, Dark2, Paired, Pastel1, Pastel2, Set1, Set2, Set3.
To view all palettes as a plot:
Use bracketed numbers to select specific colors or a range from within a palette:
col=set1[5:9]. Note that colors will be repeated if necessary. To start from a specific color in the palette, but still retain all colors in the palette, type the number for the starting color and then add that to the total number of colors in the palette.For Set1:
col=set1[5:14]To color a plot by category (from Stackoverflow)
DF <- data.frame(x=1:10, y=rnorm(10)+5, z=sample(letters[1:3], 10, replace=TRUE)) attach(DF); plot(x, y, col=c('red','blue','green')[z]); detach(DF)- The method for this may vary depending on what is being created (scatter plot, figure legend, boxplot) and how categories have been specified.
Fonts: See Quick-R.
Legend:
legend(). See Quick-R.Adding jitter when there are too many points sitting on top of each other:
plot(evals$score ~ jitter(evals$bty_avg))orplot(jitter(evals$score) ~ evals$bty_avg)Margins:
marfor margin size in lines,maifor margin size in inches. For complete information on margins, see Earl Glynn’s margins tutorial.Axes
- You cannot change axis tick mark thickness within the
default graphing capabilities. Instead:
- Suppress all axes with axes=FALSE
- Re-create the axes with the axis() command. Each y and x axis will get its own command. lwd= will control line width, or thickness, for both the axis line and the tick marks.
- This will only create partial axes that encompass the data. To make
the axes meet at 0, also create a box around the graph with
box(which = 'plot', bty = 'l') - The default axes will usually detect categorical data and label axes accordingly, but categories will need to be specified for axes created separately.
- See info from Quick-R and R in Action Ch. 3.4 for more info.
- Adding symbols to axis titles (such as mu):
plot([options], ylab=expression(bold(paste('Thickness, ',mu, 'm')))) - Axis labels:
xlab=, ylab= - If a custom axis is created, the automatically generated axis should
be suppressed.
xaxt='n'suppresses the x axis,yaxt='n'suppresses the y axis, andaxes=FALSEsuppresses both x and y axes. - Rotated axis labels in base graphics
- To rotate axis labels (using base graphics), you need to use
text(), rather thanmtext(), as the latter does not supportpar('srt'). - When plotting the x axis labels, we use
srt = 45for text rotation angle,adj = 1to place the right end of text at the tick marks, andxpd = TRUEto allow for text outside the plot region. You can adjust the value of the0.25offsetas required to move the axis labels up or down relative to the x axis. See?parfor more information. - Also see Figure 1 and associated code in Paul Murrell (2003), ‘Integrating grid Graphics Output with Base Graphics Output’, *R News,- 3/2, 7–12.
# Increase bottom margin to make room for rotated labels par(mar = c(7, 4, 4, 2) + 0.1) # Create plot with no x axis and no x axis label plot(1:8, xaxt = 'n', xlab = '') # Set up x axis with tick marks alone axis(1, labels = FALSE) # Create some text labels labels <- paste('Label', 1:8, sep = ' ') # Plot x axis labels at default tick marks text( 1:8, par('usr')[3] - 0.25, srt = 45, adj = 1, labels = labels, xpd = TRUE ) # Plot x axis label at line 6 (of 7) mtext(1, text = 'X Axis Label', line = 6)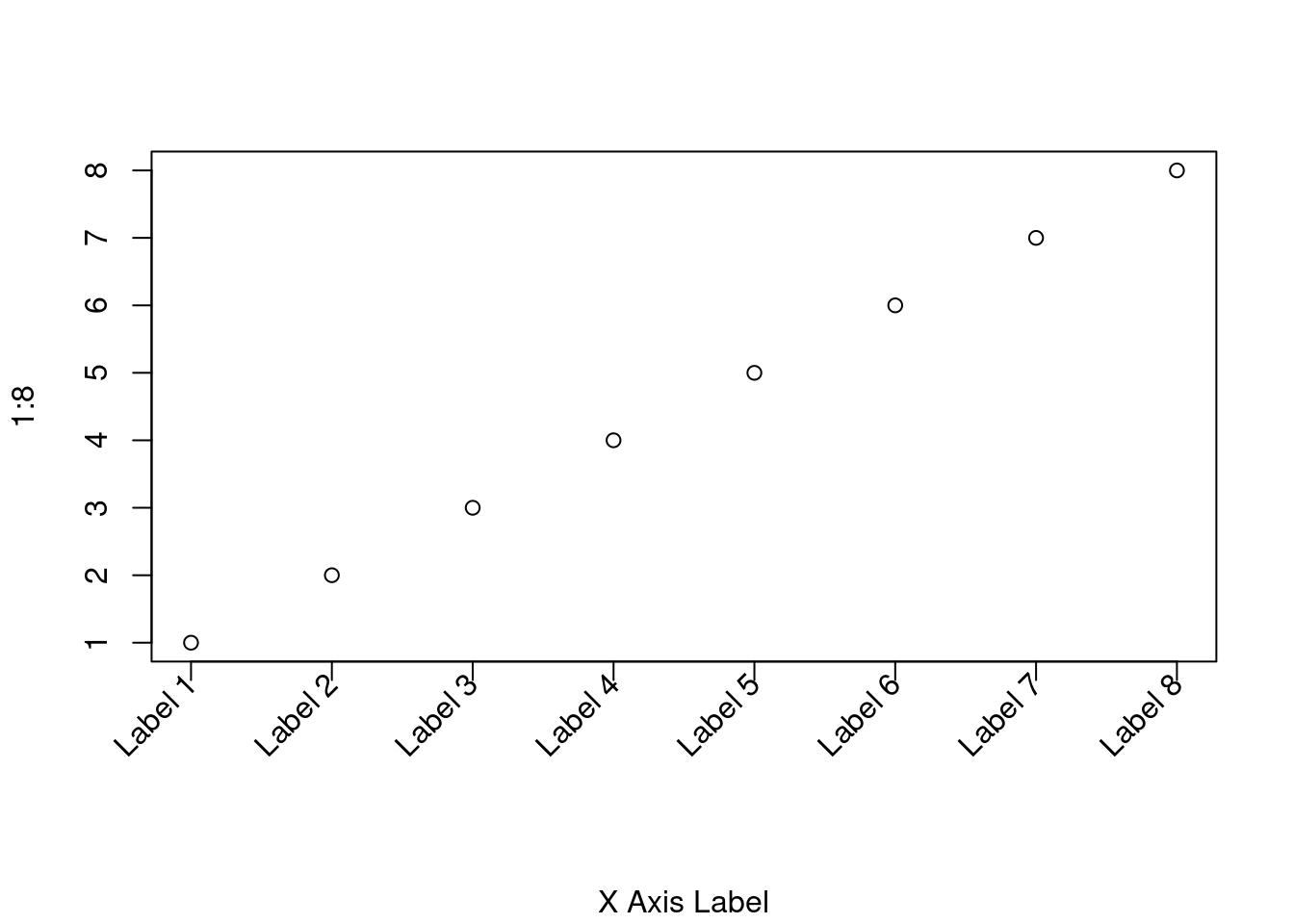
- To rotate axis labels (using base graphics), you need to use
- You cannot change axis tick mark thickness within the
default graphing capabilities. Instead:
Create figure panels with
- See R help
help(par), An Introduction to R 12.5.4 p.73, Muenchen_2009_R for SAS and SPSS Users Ch. 21.3 for more info.
- See R help
ggplot2
The ggplot2 package can generate advanced graphs (see ggplot2 documentation here and here).
- Basic quick plot:
qplot() - Build a plot progressively by repeatedly calling
ggplot(). - Other comments
- As described above, I prefer to use base graphics to create boxplots. For example, boxplots in ggplot2 do not have endcaps on the whiskers. It is possible to add them, but they are abnormally wide.
ggobi is a data visualization program that interfaces with R.
plotly is an online tool that can interface with R and Shiny. Shiny is a nice tool for creating interactive plots and presentations.